本文介绍几种常见的数据结构:栈、队列、堆、哈希表,等等。
写在前面
- 本文所有图片均截图自coursera上普林斯顿的课程《Algorithms, Part I》中的Slides
- 相关命题的证明可参考《算法(第4版)》
- 源码可在官网下载,也可以在我的github仓库 algorithms-learning下载,已经使用maven构建
- 仓库下载:
git clone git@github.com:brianway/algorithms-learning.git
Stacks(栈)
LIFO(后进先出):last in first out.
- 使用linked-list实现
保存指向第一个节点的指针,每次从前面插入/删除节点。
以字符串栈为例,示例代码:
1 | public class LinkedStackOfStrings { |
- 使用数组实现
使用数组来存储栈中的项
1 | public class FixedCapacityStackOfStrings { |
上面的实现会有几个问题:
- 从空栈pop会抛出异常
- 插入元素过多会超出数组上界
这里重点解决第二个问题,resizing arrays.一个可行的方案是: 当数组满的时候,数组大小加倍;当数组是1/4满的时候,数组大小减半。 这里不是在数组半满时削减size,这样可以避免数组在将满未满的临界点多次push-pop-push-pop操作造成大量的数组拷贝操作。
插入N个元素,N + (2 + 4 + 8 + ... + N) ~ 3N。
- N:1 array access per push
- (2 + 4 + 8 + … + N):k array accesses to double to size k (ignoring cost to create new array)
由于resize操作不是经常发生,所以均摊下来,平均每次push/pop操作的还是常量时间(constant amortized time).
Queues(队列)
FIFO(先进先出):first in first out.
- 使用linked-list实现
保存指向首尾节点的指针,每次从链表尾插入,从链表头删除。
1 | public class LinkedQueueOfStrings { |
- 使用数组实现
1 | ・Use array q[] to store items in queue. |
Priority Queues
Collections. Insert and delete items.
- Stack. Remove the item most recently added.
- Queue. Remove the item least recently added. Randomized queue. Remove a random item.
- Priority queue. Remove the largest (or smallest) item.
unordered array 实现
1 | public class UnorderedMaxPQ<Key extends Comparable<Key>> { |
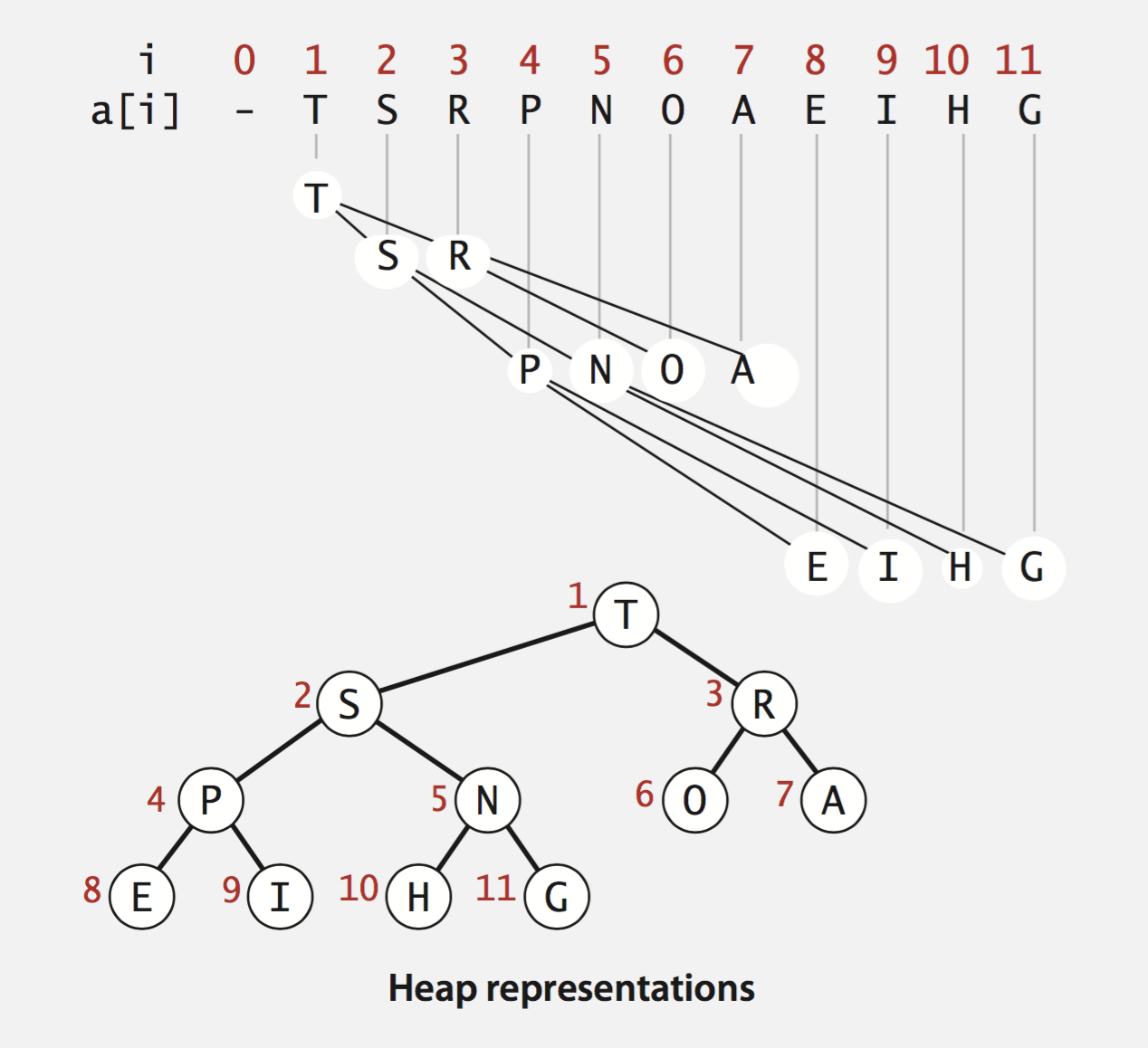
Binary Heaps(二叉堆)
使用数组来表示一个二叉堆。根节点索引从1开始。索引对应在树中的位置,最大的键值是a[1],同时也是二叉树的根节点。
- Parent’s key no smaller than children’s keys
- Indices start at 1.
- Parent of node at k is at k/2.
- Children of node at k are at 2k and 2k+1.
上浮和下沉
有两种情况会触发节点移动:
- 子节点的键值变为比父节点大
- 父节点的键值变为比子节点(一个或两个)小
而 要消除这种违反最大堆定义的结构,就需要进行节点移动和交换, 使之满足父节点键值不小于两个子节点 。对应的操作分别是 上浮 和 下沉
- 上浮:子节点key比父节点大
- Exchange key in child with key in parent.
- Repeat until heap order restored.
- 下沉:父节点key比子节点(one or both)小
- Exchange key in parent with key in larger child.
- Repeat until heap order restored
1 | /* 上浮 */ |
插入和删除
所有操作(插入和删除)都保证在log N 时间内。
- 插入:二叉堆的插入操作比较简单,把节点加在数组尾部,然后上浮即可。
- 删除最大:二叉堆的删除则是把根节点和末尾的节点交换,然后下沉该节点即可。
1 | /* 插入 */ |
最后,堆中的键值是不能变的,即Immutable.不然就不能保证父节点不小于子节点。
Symbol Tables
键值对的抽象.其中键一般使用immutable的类型,值是任何普通类型。
关于比较,所有的java类都继承了equals()方法,要求对于引用x,y,z
- Reflexive: x.equals(x) is true.
- Symmetric: x.equals(y) iff y.equals(x).
- Transitive: if x.equals(y) and y.equals(z), then x.equals(z).
- Non-null: x.equals(null) is false.
对于用户自定义的类型,一般按如下流程实现equals()方法:
- Optimization for reference equality.
- Check against null.
- Check that two objects are of the same type and cast.
- Compare each significant field:
- if field is a primitive type, use ==
- if field is an object, use equals().[apply rule recursively]
- if field is an array, apply to each entry.[alternatively, use Arrays.equals(a, b) or Arrays.deepEquals(a, b),but not a.equals(b)]
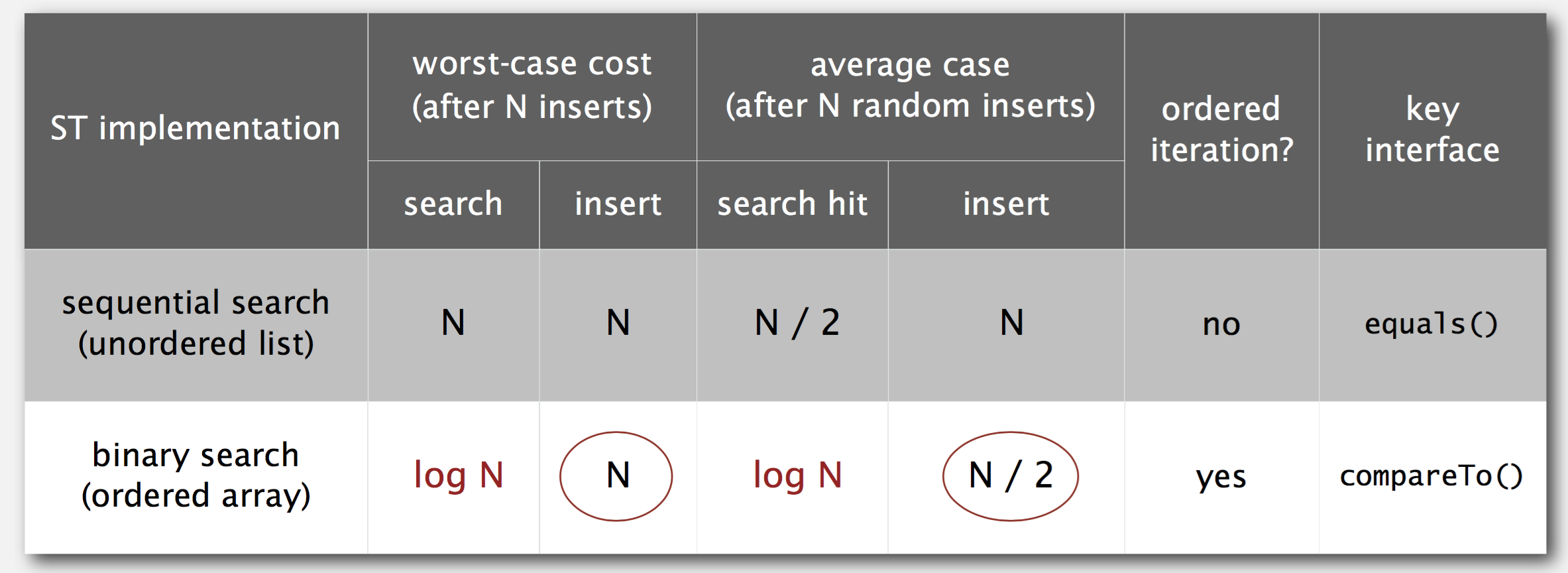
两种实现的数据结构:
- 无序链表:Maintain an (unordered) linked list of key-value pairs.
- 有序数组:Maintain an ordered array of key-value pairs.
在有序数组进行查找时使用二分查找。两种方式的对比如下图:
Hash Tables(哈希表)
上面几种数据结构都是通过遍历或者二分查找去搜寻某个元素,而哈希表则是通过一个key-indexed table来存储其中的项,即“索引”是“键”的一个函数。换句话说,哈希是通过定义一种函数/计算方法,把键直接映射成一个哈希值(再通过取余操作换算成数组的下标索引),从而定位元素,而避免耗时的逐个比较和遍历的操作。
- Hash code:An int between -2^31 and 2^31 - 1.
- Hash function. An int between 0 and M - 1 (for use as array index).
1 | //这里hashCode可能为负,且-2^31取绝对值会溢出,所以要“位与” |
所有的java类均继承了hashCode()方法来计算哈希值, 返回一个32-bit的int.默认实现是返回该对象的内存地址。对常用的类型有自己的实现,以java的String类为例子:
1 | public int hashCode() { |
hash code design.”Standard” recipe for user-defined types:
- Combine each significant field using the 31x + y rule.
- If field is a primitive type, use wrapper type hashCode().
- If field is null, return 0.
- If field is a reference type, use hashCode().[applies rule recursively]
- If field is an array, apply to each entry.[or use Arrays.deepHashCode()]
当然,这种映射并不能保证是一对一的,所以一定会出现多个键映射到同一个哈希值的尴尬情况(尤其是对数组的size取余操作后,映射到同一数组下标),即哈希冲突,这是就需要一些方法来解决。这里介绍两种常用的方法:
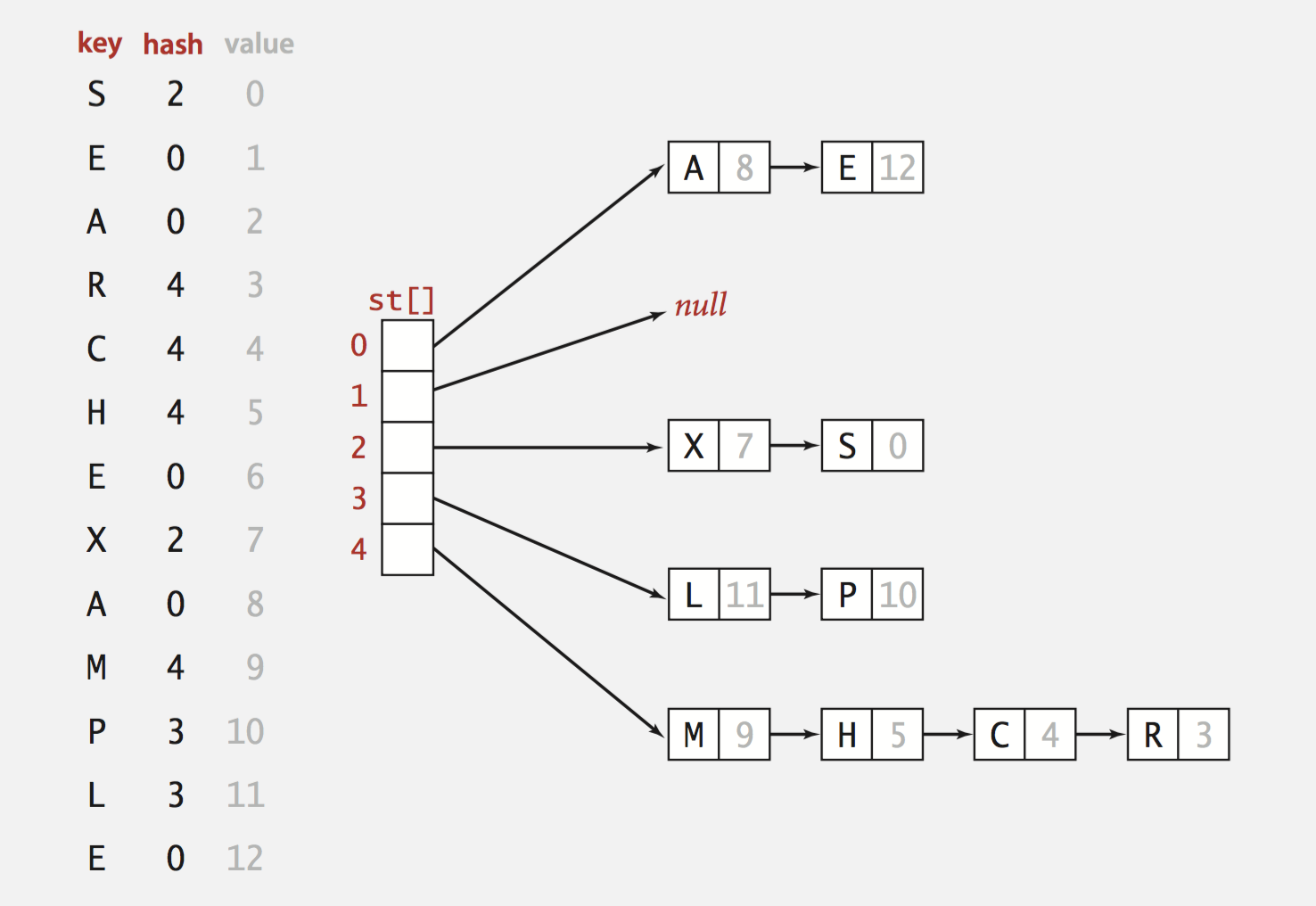
- separate chaining
- linear probing
separate chaining
Use an array of M < N linked lists.
- 哈希:将key映射到0 ~ M-1 之间的一个整数i
- 插入:将值插在第i个链的前端
- 查找:只需遍历第i个链
linear probing
开放地址:如果发生冲突,将值放入下一个空的位置.(数组尺寸 M 必须比键值对的数目 N 要多.)
- 哈希:将key映射到 0 ~ M-1 之间的一个整数i
- 插入:如果数组索引为 i 的位置为空,则把值放入,否则依次尝试 i+1,i+2等索引,直到有空的
- 查找:先找索引 i,如果被占用且没匹配,则依次尝试i+1, i+2,等等

